Meridian Design Doc 3: Evaluation Dissected
TODO
- : How to handle disputes?
- → manual resolution
- future: let people pay for claims
Introduction
MERidian stands for Measure, Evaluate, Reward, the three steps of the impact evaluator framework. The Meridian project aims to create an impact evaluator for “off-chain” networks. I.e. a network of nodes that do not maintain a shared ledger or blockchain of transactions.
This doc proposes a framework and model for Meridian that will cater initially for both the Saturn payouts system and the SPARK Station module. For a bonus point, it should be able to cater for any Station module. We believe that trying to generalise beyond these few use cases at this point may be counterproductive.
We will structure this design doc based on the three steps of an Impact Evaluator (IE), measure, evaluate and reward.
Overview
sequenceDiagram
autonumber
participant P as Peer
participant M as Measure
participant E as Evaluate
participant R as Reward
participant DB as Database
participant C as Chain
loop Measure
P->>M: Upload logs
M->>DB: Store logs
M->>C: Publish proof
end
loop Evaluate I
DB->>E: Fetch logs
E->>E: Detect fraud
E->>E: Aggregate
E->>DB: Store aggregates
E->>C: Publish proof
end
loop Evaluate II
DB->>E: Fetch aggregates
E->>E: Calculate reward shares
E->>C: Publish reward shares
end
loop Reward
R->>C: Create payment splitters
P->>C: Claim FIL
end
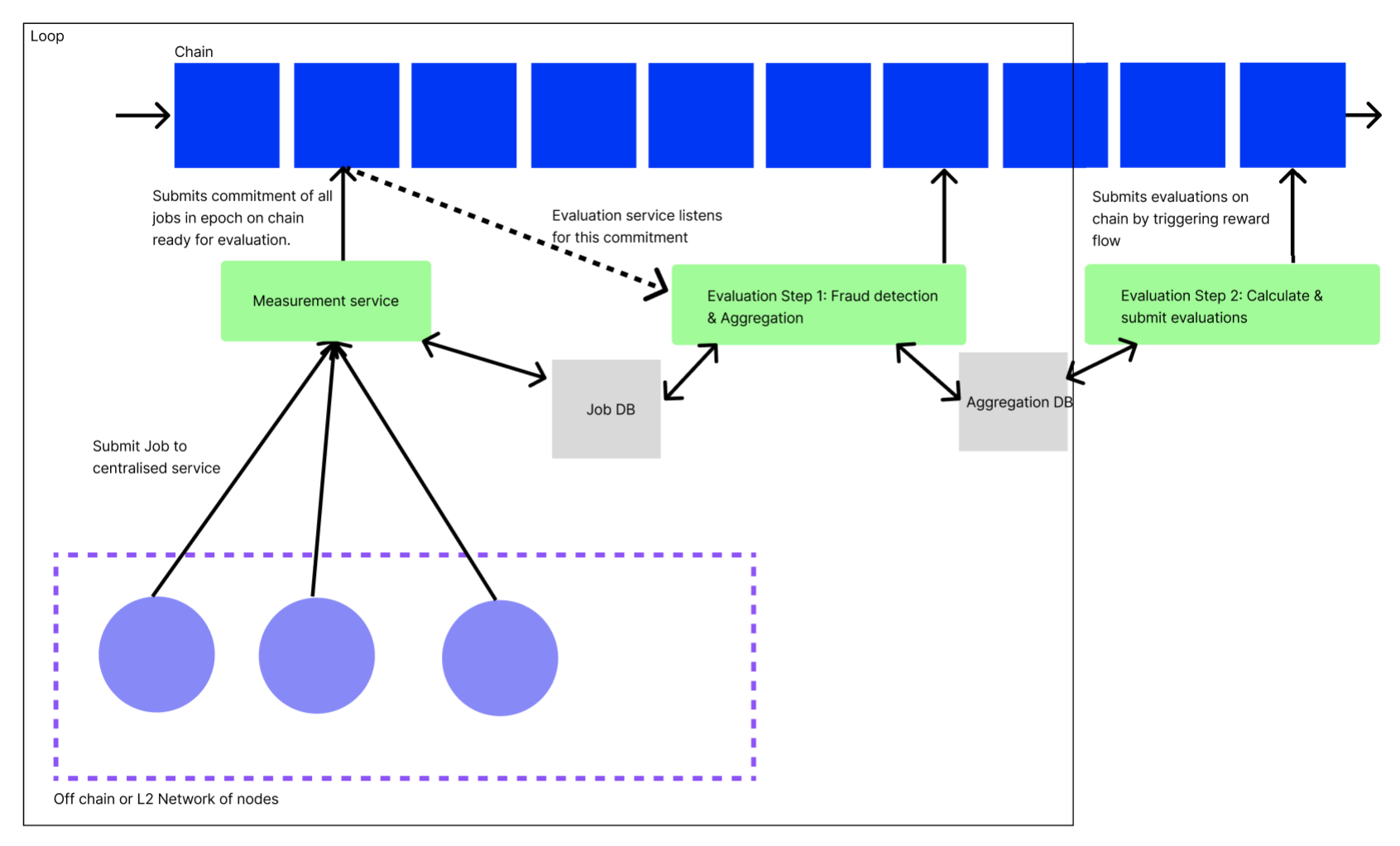
Use of centralized services
We have chosen to start the Meridian design supported by a minimal set of centralized and trusted services (previously called orchestrator). See for an exploration of alternatives.
A fully trustless model is to be developed as a very next step, because it brings important benefits for a rewards system:
- Trustless: There are no hidden parts of the system. All computation can be inspected by all peers.
- Safe: No party is responsible / liable for running the system
However, only using smart contracts poses unsolved design challenges:
- How to avoid high gas cost due to frequent contract invocation (O(n) vs O(1) when using a service that aggregates and then commits)
- How to store and work on large amounts of data
Store & commit
A pattern in the system is for centralized components to both store their results in a centralized database, and commit a proof of their results to the decentralized blockchain (through smart contracts).
This enables other services to consume the raw results produced, to implement further operations. This also adds verifiability, which is a crucial aspect of reward systems. Peers shouldn’t have to trust the system’s operators.
For example, here is how the measure service passes data on to the evaluate service, while publishing commitments on chain:
flowchart
M[Measure Service] --raw results--> MDB[Measure DB]
M --commitment--> MC[Measure Contract]
MDB --raw results--> E[Evaluate Service]
E --commitment--> EC[Evaluate Contract]
E --raw results--> EDB[Evaluate DB]Measure
In the measure step, we refer to each atomic item that gets measured as a job. For example, each retrieval served by a Saturn node is a job. For Spark, each retrieval made from an SP is a job.
This step is implemented using 3 components:
- A centralized measure service
- A centralized measure database
- A measure smart contract
Peers periodically submit measurements (job logs) to the measure service, which stores them raw in its database, for future consumption by the evaluate pipeline.
The measure service will also periodically create Merkle trees of all measurements received (since the last proof). The root hash is published to the chain, the full tree is stored in the database. This allows peers to verify that their job logs have been included, taking steps towards a fully trustless model.
sequenceDiagram
autonumber
participant P as Peer
participant S as Service: Measure
participant D as DB: Measure
participant C as Contract: Measure
loop Store
P->>S: Upload measurements
S->>D: Store measurements
end
loop Commit
D->>S: Fetch measurements
S->>S: Create Merkle tree
S->>D: Store Merkle tree
S->>C: Call with Merkle root hash
C->>C: Emit hash
endProof of Inclusion
Meridian implementers can create a verification service, which lets peers verify inclusion by exposing the relevant nodes of the matching merkle tree.
sequenceDiagram
participant P as Peer
participant S as Service: Verify
participant D as Database: Measure
P->>S: submit log hash, merkle root hash
S->>D: fetch merkle tree
S->>P: return relevant nodesSee also:
Data Model
Job logs
Job logs are periodically submitted by the peer to the measure service. This raw log of work done is the basis for the whole Meridian pipeline.
[
// Generalized record
{
"job_id": "<UUID or CID>", // Unique job id
"peer_id": "<Libp2p Peer ID>", // Who completed the job
"started_at": "Timestamp", // When did the job begin
"ended_at": "Timestamp", // When did the job end
// Any other fields that are useful measurements of work done
}
// Example Saturn record
{
"job_id": "abcdef",
"peer_id": "<Libp2p Peer ID>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:58.62+00",
"num_bytes_sent": 240,
"request_duration_sec": 10,
"ttfb_ms": 35,
"status_code": 200,
"cache_hit": true
}
// Example SPARK record
{
"job_id": "abcdef",
"peer_id": "<Libp2p Peer ID>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:58.62+00",
"status_code": 200,
"signature_chain": "<signature chain>",
"num_bytes": 200,
"ttfb_ms": 45
}
]On-chain commitment
Periodically, the measure service submits a commitment of work received to the chain, via the measure smart contract. After creating and storing a merkle tree over the logs, the root hash is published together with the measurement epoch.
{
"root": "<merkle root hash>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:57.62+00"
}Implementation
 https://github.com/filecoin-station/meridian-measure-service/tree/main
https://github.com/filecoin-station/meridian-measure-service/tree/mainEvaluate
At this point we have a table of logs in the above data model, stored in an off-chain data store. The next step is to evaluate over the logs from the current measurement epoch, using the evaluation function.
Evaluation Function
In general, for evaluation fields, for node where , and with logs and evaluations on those logs and evaluation function , we can calculate the evaluation output as
where and is the evaluation of node .
In the case of Saturn, the evaluation function is a function of number of bytes sent, TTFB and the request duration. This is calculated by the Saturn payouts system.
In the case of Spark, the evaluation function is simply a count of the number of successful requests with valid signature chains a Station has performed. Specifically, for node ,
where if the log with index of node is valid and otherwise.
The Saturn evaluation function is more complicated . See https://hackmd.io/@cryptoecon/saturn-aliens/%2FMqxcRhVdSi2txAKW7pCh5Q for more details.
Multi stage evaluation
In Meridian, evaluation is a 2 stage process. Evaluation stage i is a data preprocessing pipeline, that periodically pre-filters and aggregates measurement results. This smaller dataset is then consumed by evaluation stage ii, which is executed once before the rewards phase.
The 2 stage design is one of the lessons from the Saturn project: Data needs to be aggregated and pre-filtered, as otherwise e.g. a once-a-month evaluation run will operate over too large a dataset and pose serious scaling issues.
Conveniently, fraud detection is also a 2 stage process, and each evaluation stage comes with one fraud detection stage.
Evaluation Stage I: Data preprocessing
The data preprocessing pipeline is executed whenever the measure service has committed an inclusion proof on chain. It takes the raw logs from associated measurement epoch, performs its preprocessing steps, and finally stores & commits.
sequenceDiagram
autonumber
participant E as Service: Evaluate Stage I
participant DM as Database: Measure
participant DE as Database: Evaluate
participant C as Chain
DM->>E: Fetch logs
E->>E: Detect fraud
E->>E: Aggregate
E->>DE: Store aggregates in buckets Honest/Fraudulent
E->>C: Publish proof
Fraud Detection
Based on the network-specific fraud detection function, raw job logs are aggregated into two buckets:
- Honest logs: Logs used for later processing in evaluation stage ii and reward
- Fraudulent logs: Logs kept for reference
The fraud detection function maps an individual log line to boolean fraudulent status:
flowchart TD
subgraph Logs
L1[Log]
L2[Log]
L3[Log]
end
subgraph Buckets
BH[Honest logs]
BF[Fraudulent logs]
end
Logs--detect fraud-->Buckets
L1[Log] --> BH
L2[Log] --> BH
L3[Log] --> BF
For SPARK for example, the fraud detection function verifies a log’s UCAN signature chain. If the signature chain holds, the log line will be aggregated into Honest logs, otherwise Fraudulent logs.
Aggregation
Logs from both buckets will be aggregated, and those aggregations stored in a database. A merged aggregate will be committed on chain.
However, only logs from the Honest logs bucket will count when evaluation stage ii determines the peer’s impact on the system.
flowchart TD
subgraph Buckets
BH[Honest logs]
BF[Fraudulent logs]
end
subgraph Aggregates
AH[Honest logs]
AF[Fraudulent logs]
end
subgraph Database
TH[Honest logs]
TF[Fraudulent logs]
end
BH --> AH
BF --> AF
AH --> TH
AF --> TF
AH --> Merge
AF --> Merge
Merge --> Commitment
On-chain commitment
The on-chain commitment contains aggregated measurements from both buckets Honest logs and Fraudulent logs, in order to commit to a sum of work done. No further details about fraud detection results are leaked, to prevent gaming the system.
// General commitment shape
{
// The .root hash of the measurement commitment that was aggregated over
"measurement_root": "<merkle root hash>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:57.62+00",
"measurements": {
"honest": {
"log_count": 1000,
// Any properties that need to be fed to the evaluation function,
// aggregated
},
"fraudulent": {
// Same shape as above
}
}
}
// Example Saturn commitment
{
"measurement_root": "<merkle root hash>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:57.62+00",
"measurements": {
"honest": {
"log_count": 13,
"num_bytes": 1000
},
"fraudulent": {
"log_count": 2000,
"num_bytes": 100
}
}
}
// Example SPARK commitment
{
"measurement_root": "<merkle root hash>",
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:57.62+00",
"measurements": {
"honest": {
"log_count": 13,
"num_bytes": 1000
},
"fraudulent": {
"log_count": 2000,
"num_bytes": 100
}
}
}Proof
The attached measurement root lets peers verify that their log line was included in the aggregation. There is no further proof of which log line has counted towards the aggregation (or been ignored due to fraud) in order to prevent gaming the fraud detection function.
Fraud detection is a private process and therefore also no proof will be created for this function.
Evaluation Stage II
At the end of each payment epoch, the evaluate stage ii service converts preprocessed aggregated logs (from the Honest logs bucket) into evaluation results.
It also executes a 2nd round of fraud filtering.
It asks for human review before triggering the reward phase by calling the rewards factory contract with batches of evaluations.
sequenceDiagram
autonumber
participant E as Service: Evaluate Stage II
participant DB as Database: Evaluate
participant C as Contract: Rewards Factory
DB->>E: Fetch Honest logs aggregates
E->>E: Detect and discard fraud
E->>E: Evaluate
E->>E: Ask for human review
E->>E: Create batches of evaluations
loop For each batch
E->>C: Call with batch of evaluations
end
The evaluation process runs off chain, because the dataset (all aggregated measurements produced by evaluation stage i) is too large to be handled by smart contracts.
In order for the rewards factory contract to be callable even with a large size of peers, the evaluate stage ii service needs to batch its calls into dynamically sized buckets, given known smart contract size limitations.
Fraud detection
Multiple processes can mark peers or logs as fraudulent, in between measure and evaluate. For example, the Saturn Orchestrator can mark a peer as fraudulent when it fakes its speed test results.
Therefore, all logs that are part of the Honest logs buckets but have later on been flagged as fraudulent (or associated with a peer that has been flagged) will not be fed into the evaluation function.
Proof
Proofing that the correct evaluation computation was run over the correct dataset, and that the right result was shared, is still a matter of research.
TODO : Add more details
However, since the evaluation function doesn’t contain any secrets (it is independent of fraud detection, which should stay private), it can be fully open sourced, which helps with trust and verifiability.
Human Review
Before finally submitting evaluation results, there is a phase of human review. Should the evaluation results for some reason be off, the evaluate service can be patched and the evaluation phase ii started again.
Should there be a problem in the previous steps (measure, evaluate phase i), their results have already been committed and can’t be adjusted any more (for this payment epoch).
Data Model
At the end of evaluation stage ii data of following shape is committed on chain by calling the rewards factory contract.
{
"started_at": "2023-05-01 00:52:57.62+00",
"ended_at": "2023-05-01 00:52:57.62+00",
"payees": [{
"address": "f1...",
"proportion": "0.4", // Fraction of the reward pool
"fraud": "0.1" // Fraction of fraudulent logs amont all of the
// payee's logs (which have been discarged)
},{
"address": "f1...",
"proportion": "0.6",
"fraud": "0"
}],
}I.e. for each epoch we know what proportion of the overall tokens will go to each node.
Reward
The reward step consists of 2 smart contracts. The evaluate service calls the first, which then deploys the other.
For each batch of evaluations submitted to the Rewards Factory contract, one Payment Splitter contract is deployed. Each Payment Splitter contract has inlined the reward shares. Each share can be claimed by the designated peer.
sequenceDiagram
autonumber
participant E as Service: Evaluate
participant F as Contract: Rewards Factory
participant S as Contract: Payment Splitter
participant P as Peer
E->>F: (Call with batches of evaluations,<br/>see Evaluate)
loop For each batch
F->>S: Deploy contract
end
P->>S: Claim FILflowchart TD
subgraph Service: Evaluate
b1[Batch of evaluations]
b2[Batch of evaluations]
end
b1--call-->F[Contract: Rewards Factory]
F--deploy-->S[Contract: Payment Splitter<br />- f1aaa: 1FIL<br />- f1bbb: 2FIL<br />...]
subgraph Peers
p1[Peer: f1aaa]
p2[Peer: f2aaa]
end
p1--claim-->S
p2--claim-->S
Pull vs push payments
It is important for peers to claim (pull) their rewards, instead of for the system to send out (push) rewards, for multiple reasons:
- The system would have to pay the transaction gas fees
- This gives peers the freedom to claim whenever they want (e.g. tax benefits), or not to claim at all
- This further decouples the system from the system’s operator, which helps with liabilities
Pull payments require a balance
In order for a peer to claim their rewards, they will need to have enough balance in their wallets to pay the gas fees for calling the smart contract. This usually means sending some FIL onto your wallet before being able to claim rewards.
In order to help peers with initial rewards payment, an option to push payments could be added, where the smart contract will transfer out the reward, subtracting the gas fees it has to pay itself. While potentially convenient for the peer, this undoes the decoupling benefit of pull payments, plus adds complexity for gas estimation.
Reward contract balance
The reward contract needs to have a balance, in order for peers to be able to claim their FIL from it. Ideally, the clients of the system implementing Meridian will pay their service fees directly into the rewards contract. As long as this flow is not yet established, the team operating the service needs to manually top up its balance.
If a peer was flagged as fraudulent after evaluate and before reward, its revenue share is kept and moved to the next cycle’s reward pool.
Smart Contracts
Depending on how complex contracts turn out to be, hire contractors or write ourselves. Our current thinking is that contract work will be simple enough (either because contracts are simple or existing contracts can be reused), that we would prefer to write the contracts ourselves. This puts is more in control, and alleviates timelines / cross team orchestration.
Independent of which team creates the contracts, audits will be required anyway.
Specs
- Measure
Testing
Testing will depend on the choice of framework we use to develop the smart contracts. The recommendation is that we proceed with foundry because it has built in invariance testing and auto generates rust bindings for the contracts which are useful for integration tests.
Smart Contract Testing
- We can write some unit tests in solidity that test basic contract functions such as claiming a payout, etc. With foundry we can write these tests in solidity.
- Invariance testing. This is built in foundry or can be done with a separate library such as echidna. This implements fuzz testing to the contract as a whole.
- Static analysis. There are already established analysis tools for EVM smart contracts and we should use them.
One caveat with testing FVM smart contracts is that if we want to use filecoin specific features (eg. Filecoin addresses) in our contracts then we would be relying on using filecoin pre-compiles and that will break a lot of testing libraries. A naive solution could be to maintain two versions of each contract. The Saturn team also started working on a local FVM test executor written in Rust that allows to run unit tests on solidity smart contracts that use filecoin precompiles. This executor is still rudimentary and needs improvement to be a reliable testing tool.
Unit Tests
Each component should have unit tests to make sure functionality is working. For example we should have extensive unit tests for: log commitment scheme, evaluation functions, etc.
Integration Tests
If we have bindings for the contracts, we can easily write integration tests for some end to end flows that run on calibration net. This just requires a burner wallet with some test fil in it. Saturn already has examples of this.
Auditing
After we complete our smart contracts, we should have them audited and publish the audit publicly.
Observability
Take inspiration from the Saturn internal dashboard.
Create a generalized dashboard template for all Meridian systems.
SPARK x Meridian roadmap
SPARK will be the first Meridian implementation. The use case of SPARK will be used to create the reusable infrastructure (services & smart contracts) that Meridian will offer to future implementors.
Quality criteria
- For each service or smart contract
- Testsuite
testnetdeployment
mainnetdeployment
- For each smart contract
- Audit
- Static analysis
- For each service
- Observability through Sentry & Grafana
No walking skeleton
While it is a popular pattern (and one liked by the team) to first create a walking skeleton with all the components of a software system in it’s most basic form talking to each other, it is not a great fit for Meridian.
- The sooner the finished measure step is deployed, the sooner we will collect real data that will later be consumed by the following steps. Therefore, developing the steps in parallel will shift the timeline unfavourably
- The steps have clear boundaries with well enough defined Interfaces, thanks to the theoretical foundation of the Impact Evaluator Framework
- A deployed measure step can already collect data, while a deployed yet unfinished evaluate step shouldn’t start evaluating them
- Sequential flow of development fits sequential flow of system
The team is therefore going to implement measure, evaluate and reward in the traditional waterfall model. One could also argue that the result of this document’s roadmap will be just this walking skeleton.
Next: What are we going to do until Labweek?
- Bug fixes
- Improvements
- Non-technical tasks
- Prepare talk(s)
| Item | DRI | Notes |
|---|---|---|
| Interface with legal | PM | |
| Business model exploration | PM | |
| Boost interface | Eng Lead | |
| Smart contract contractors | PM | Contractor? |
| Smart contract auditors | PM | Contractor |
| Measure Eng work | Eng Lead | |
| Evaluate Eng work | Eng Lead | |
| Reward Eng work | Eng Lead | |
| Meridian Website | PM | Contractor |
| Update Station Website | PM + Contractor | Contractor |
| Lab week planning | PM | |
| Swag | PM | |
| Product market fit work | PM |
Notes 2023-08-03
Need a smart contract that is running the whole loop
Want it to operate as close as you can to how block rewards operate
Structure on chain that nobody controls
Entity that nobody controls that is on chain, that runs the process of rewarding
Look at Juan’s workshops into how contract structure should work
Taking blockchain reward model and not change it at all
Overall smart contract for the IE
Per round
Sampling steps into the SP to find a CID
Orchestrator should sample CIDs
There is no list of CIDs anywhere
Flesh out the e2e structure of Meridian and deploy a version of it, even if measurement and rewarding isn’t as good as it should be.
For small amounts of reward, it wont be worth doing fraud
Honest vs fraudulent log classifier
Block reward model has a concrete time structure